Introduction
AI transformers have rapidly become one of the most popular and effective architectures in natural language processing and artificial intelligence. But what exactly are transformers, and how do they leverage embeddings to achieve state-of-the-art results on tasks like translation and text generation?
In this post, I’ll attempt to demystify tokens, embedding, and transformers by unveiling the magic behind their near-human linguistic abilities using a simple analogy – language is like LEGOs! While the overall goal is to introduce you to the key concepts, you’ll find additional links at the bottom of the post that will allow you to dive deeper.
Let’s get started by talking about the role of tokens.
Tokens: The Building Blocks of Language
Before diving into transformers, let’s talk about a key aspect of AI and transfomers: the token. You can think of sentences and words as molecules, whereas tokens are the atoms that make them up. Just like molecules are built from atoms, sentences are built from smaller token units.

Ever thought of language as a complex LEGO masterpiece? Imagine words, sentences, and paragraphs as an intricate LEGO creation composed of many tokens.

While not as robust as the previous image, the following sentence will be converted into 5 tokens (or LEGO bricks if you’d like to think of it that way):
She ate the pizza.

Note: You can use OpenAI’s online tokenizer tool to see how words are converted into tokens. Additional information about tokens can be found in their documentation.
Here’s another example of how words map to tokens:
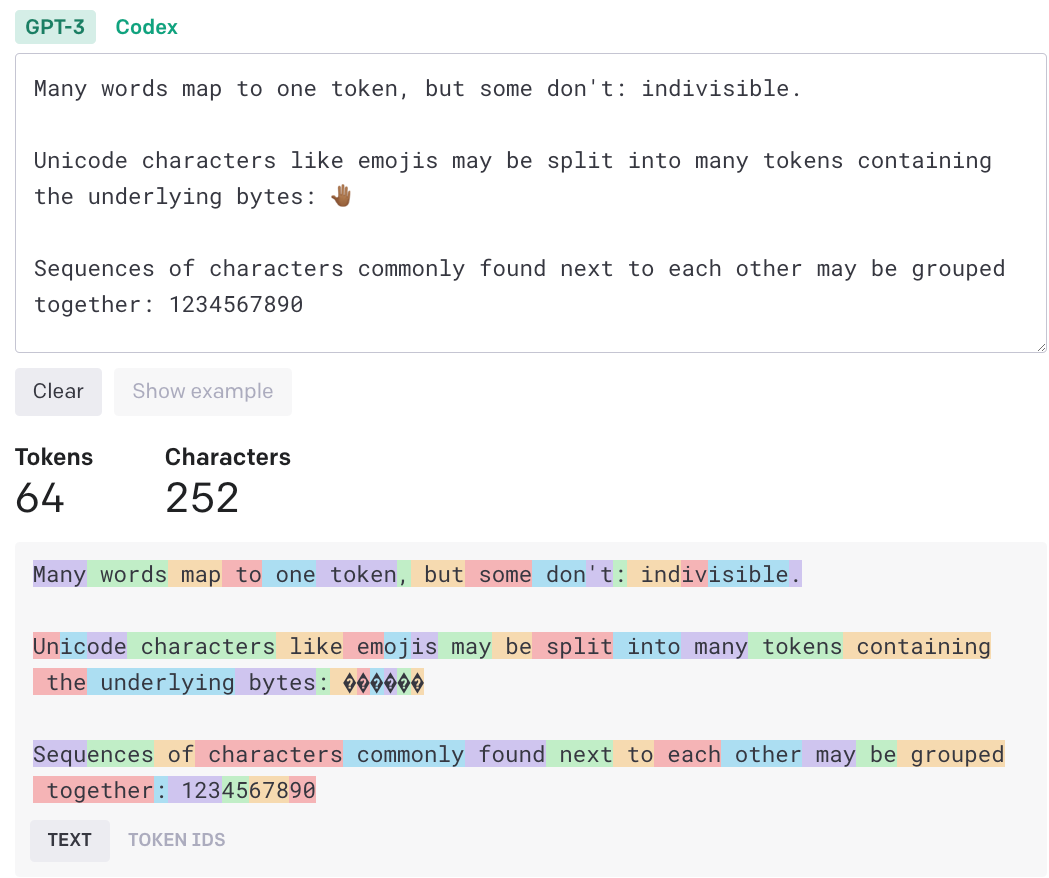
By converting language into tokens, AI transformers can build meaning from language. But, there’s more to the token story.
Embeddings: A Token’s Identity
Tokens play a vital role in language processing, but they require a universal descriptor. This is where embeddings enter the scene. Tokens are like the basic LEGO bricks – they provide the fundamental building blocks. But on their own, the transformer has no way to distinguish between bricks.
Embeddings are like the stickers, patterns, or colors added to the bricks to give them unique identities. Each blank brick now has decorative markings that set it apart.
For example, the token for “ate” may be decorated with a green and white sticker marker, while the token for “pizza” has vivid red and white stripes. The embeddings add symbolic meaning to the initially generic tokens. Now the transformer can easily identify each distinct “token-brick” by its decorative pattern or colors, similar to how we can differentiate LEGO pieces by appearance. These embedding “markings” allow the model to represent the unique meaning of each token.
Imagine you’re building a LEGO model with a friend. Instead of asking, “Can you hand me the brick that says ‘She’ on it?”, it’s more intuitive to request, “Can you hand me the blue circle brick?”. In human terms, both questions might lead to the correct brick, but for machines, a more universal identifier, like the shape and color, simplifies the process.
Take the sentence “She ate the pizza”. This can be visualized using our LEGO analogy:
- [She]: [Blue, Circle]
- [ate]: [Green, Rectangle]
- [the]: [Yellow, Square]
- [pizza]: [Red, Triangle]
This works well from a human perspective, but how do machines interpret discrete words? Machines rely on numbers, not words. This brings us back to embeddings – the secret sauce behind Large Language Models (LLMs).
Machines would convert the above tokens into numerical vectors:
- [She]: [0.1, 0.3, 0.5]
- [ate]: [0.7, 0.2, 0.1]
- [the]: [0.3, 0.1, 0.9]
- [pizza]: [0.2, 0.6, 0.1]
These vectors encapsulate the essence of each word, making it digestible for AI transformers. Some embeddings even capture the order of words or differentiate content types, such as questions from answers. In practice, an LLM would have more extensive values, enabling it to grasp the nuances and associations between words (for example, apple and banana are both a type of fruit, car and truck are both a type of automobile). With these vectors, transformers can process language by focusing on these numerical representations and their interrelations.
For more information on how embeddings are used to make sense of words and sentences, check out What are Word and Sentence Embeddings? by Luis Serrano. If you’d like to generate embeddings from text you can use OpenAI’s embeddings API (many others also exist).
Now that you’ve been introduced to tokens and embeddings, let’s take a closer look at the role of transformers.
Transformers: Assembling Linguistic LEGOs
Imagine sharing a memory with a group of friends: “She ate the pizza.” But you’re among Spanish speakers! Fear not, the transformer understands each token’s nuance. At their core, transformers are composed of an encoder and a decoder. The encoder reads in an input sequence, like a sentence, and produces an encoded representation of its contents. This compact encoding captures the contextual meaning of the full input. The decoder then takes this encoded representation and generates an output sequence from it.
- The Encoder: Interprets the essence of each English token, keeping the core message intact.
- The Decoder: Building upon this input, it selects Spanish tokens: “Ella comió la pizza.” Something called “attention” guides each token into place (more on this in a moment).
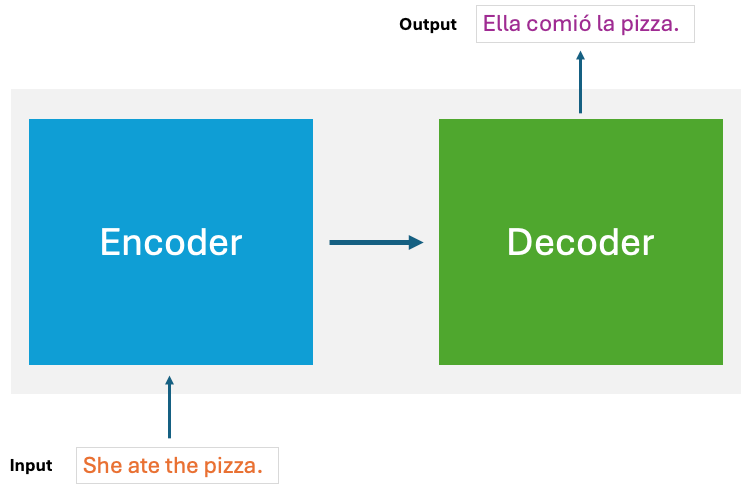
Say we want to automatically translate the sentence “She ate the pizza” from English into Spanish. Here are the general transformer steps:
- An encoder module reads the input sentence tokens and generates an encoded representation of its meaning. This is like a summary of the overall context.
- Attention layers connect the encoder and decoder, allowing the decoder to focus on relevant words in the original sentence as it generates the output. The attention mechanism gives transformers their ability to draw global dependencies between input and output.
- A decoder module takes this encoded context and outputs the Spanish translation word-by-word: “Ella comió la pizza”.
Attention: The Transformer’s Guide
Picture the encoder and decoder modules as being like towering, multilayer LEGO creations. Each layer incrementally processes the input tokens in a more complex way. Both the encoder and decoder are composed of smaller building blocks stacked on top of each other. Each block applies layers of multi-headed self-attention and feedforward neural networks to the data.

Here’s what’s inside these LEGO layers:
- Multi-headed Attention: These are our diligent LEGO designers. Just as designers consider how each LEGO piece relates to the others, multi-headed attention assesses how each token interacts with every other token in the sentence. For instance, it might recognize the tight relationship between “She” and “ate”, or how “ate” connects with “pizza”, capturing the broader context of the sentence.
- Feed-forward Networks: Picture these as the meticulous LEGO builders. After the designers (multi-headed attention) provide the blueprint, these builders refine it. They work on each token in parallel, ensuring they fit seamlessly within the overall structure. This could mean adjusting a token’s representation to better mesh with its neighboring tokens, thus refining the entire sentence’s representation.
Collectively, multi-headed attention and feed-forward networks collaborate at each layer, progressively enhancing token representations. It’s similar to stacking LEGO layers to build a richer, more detailed structure. Through this process, transformers can grasp intricate linguistic patterns and relationships, allowing for accurate translations and other language completion tasks.
Summary
That’s a wrap for this post! Is there more to the AI transformer story? Absolutely! However, the goal of this post is to introduce you to the main concepts and help you understand how they fit together. If you’d like additional details I’d recommend making time to read through the articles in the Additional Resources section below.
Let’s sum up what was covered:
- Think of tokens as atoms that combine to form sentences or linguistic “molecules.” Analogously, if sentences are LEGO structures, tokens are the individual LEGO bricks. For instance, the simple sentence “She ate the pizza” gets broken down into tokens, each represented by numeric embeddings.
- Embeddings are dense numeric vectors that capture semantic meaning for each token. They bring discrete language into a continuous vector space that transformers can analyze. The embeddings serve as the mathematical language and data representation that transformers operate on.
- Transformers are AI models that excel in tasks like translation and text generation by treating language as building blocks called tokens.
- At the heart of a transformer are an encoder and a decoder. The encoder absorbs a sentence, grasping the essence of its tokens. The decoder then creates an output, like a translated sentence, building on the context captured by the encoder. Throughout this process, mechanisms like multi-headed attention and feed-forward networks inspect and refine tokens, much like LEGO designers and builders perfecting a structure.
In sum, transformers master language by breaking it down into manageable chunks (tokens), giving each chunk a numeric identity (embeddings), and then working with these chunks to produce meaningful outputs.
Found this information useful? Please share it with others and follow me to get updates:
- Twitter – https://twitter.com/danwahlin
- LinkedIn – https://www.linkedin.com/in/danwahlin
Additional Resources
- The Illustrated Transformer
- How GPT models work: accessible to everyone
- The Transformer architecture of GPT models
- What are Word and Sentence Embeddings?